
Beyond Prompts: Why Context Management significantly improves AI Performance
Just because a model can handle a lot of context, doesn't mean it should. Here's how and why you can manage the context window better to make better use of LLMs

When people discuss improving AI outputs, they often focus on prompt engineering or choosing the right model. But there's a critical factor that affects performance more than most realize: how you manage the AI's context window.
Recent research shows that context management can dramatically impact AI performance - more than most users account for. The difference between a well-managed and poorly-managed context can be the difference between insightful, accurate responses and confused, inconsistent ones.
This isn't just about technical optimization - it's about practical strategies that anyone can use to get significantly better results. Let's explore why context matters so much and the straightforward techniques that can transform your AI interactions.
What's Actually Happening Under the Hood
Large language models (like GPT-4o and Claude Sonnet 3.7) don't process raw text directly – they work with tokens. Every input gets encoded into these token building blocks for the model to understand, and every response gets decoded back into human-readable text.
You can visualize tokens using the Tiktokenizer as you can see below.
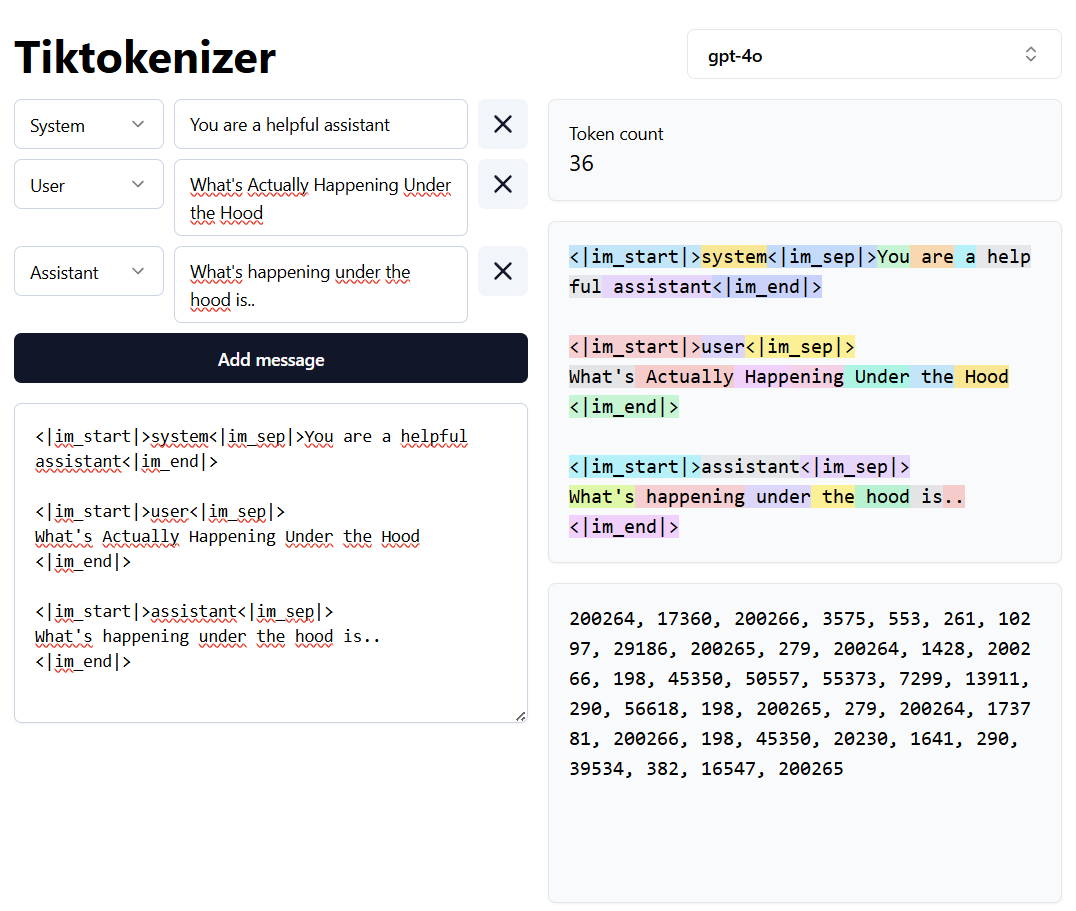
So a model processes tokens. But there’s a limit to how many tokens it can read at once, and that is called the maximum context window.
Modern LLM’s can generally handle at least 32,000 tokens (roughly 24,000 words) , with some models like Gemini Flash 2.0 offering massive 1 million token windows (enough for entire books). For reference, Harry Potter and the Sorcerer’s Stone is about 77.000 words long. That translates to roughly 100k tokens. You could fit this 10 times into Gemini Flash 2.0, and it would still be able to answer questions about it!
But here's the crucial insight: Just because an AI can process more text doesn't mean it will process it well. In fact, research consistently shows that performance on complex tasks actually degrades as context length increases.
From Simple Recall to Deeper Reasoning: The "Needle in a Haystack" Evolution
When AI benchmarks first appeared, we often used the "needle in a haystack" test. Basically, researchers would hide a specific fact (the needle) in a huge block of text (the haystack) to see if an AI model could quickly find it. Over time, models got incredibly good at this. Today, finding a specific fact, even within massive texts spanning millions of tokens, is something models like GPT-4o and Gemini Sonnet 3.7 do almost perfectly.
Example of a needle in a haystack test:
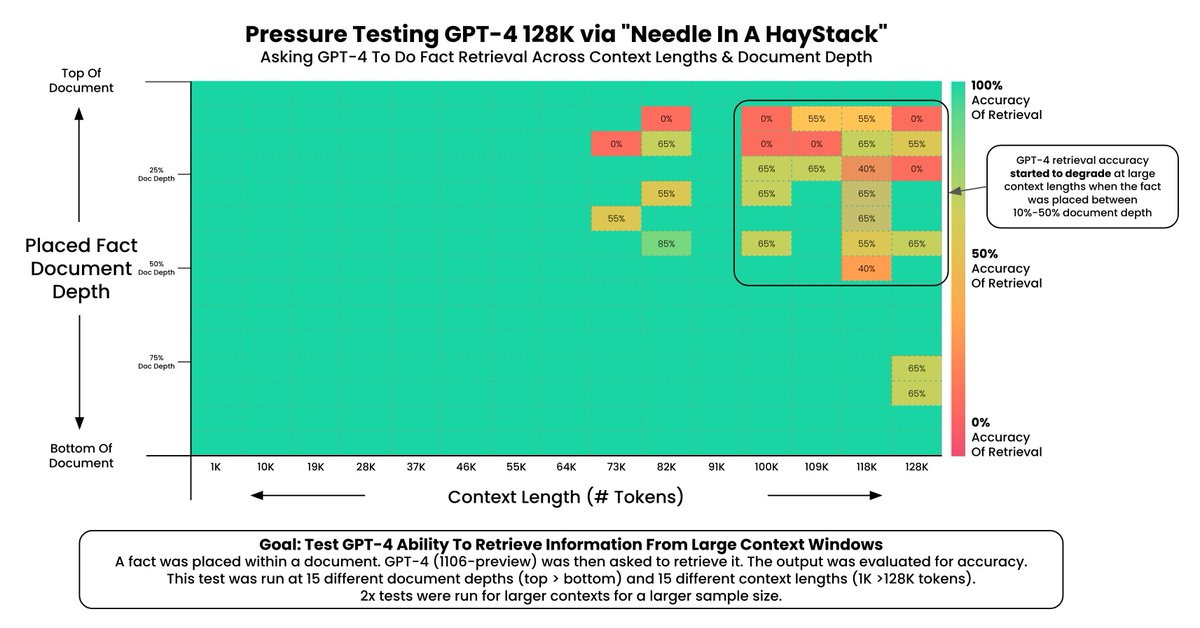
With the current generation of LLMs, these test are 99.9% green, with almost perfect recall. The image above shows the results with the old GPT-4 model, which shows almost perfect results up to 100k tokens.
But now that AI excels at simple fact-finding, benchmarks have evolved. Instead of testing whether a model can recall a specific detail, newer tests dig deeper. They examine how well the AI can piece together information spread across different sections, maintain logical consistency, or handle complex, multi-step reasoning tasks.
This shift matters because real-world AI applications rarely involve just recalling isolated facts. Instead, they require synthesizing ideas, making nuanced connections, and maintaining coherence over longer interactions. This are exactly the areas current benchmarks now prioritize.
The High Context Performance Problem
As it turns out from more recent benchmarks: AI models perform significantly worse on complex tasks as context length increases.

In benchmarks from late 2024 and early 2025, researchers consistently found dramatic performance drops:
Models show accuracy declines of 50-70% when handling complex reasoning tasks as context grows from 1,000 to 32,000 tokens
GPT-4o's performance on tasks requiring connecting ideas across a document drops from 99% to below 70% accuracy when context exceeds 32,000 tokens
Technical writing quality decreases by over 40% when context length doubles, with narrative consistency suffering the most
Financial analysis tasks show a 73% accuracy drop when analyzing reports in 128k token contexts versus 8k tokens
Sources:
[2308.14508] LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding
[2307.11088] L-Eval: Instituting Standardized Evaluation for Long Context Language Models
[2502.05167] NoLiMa: Long-Context Evaluation Beyond Literal Matching
While these models excel at finding specific facts in long texts (like locating a character's name in a novel), they struggle with tasks that require:
Connecting ideas across different parts of a document
Following complex multi-step instructions
Maintaining consistent reasoning across long outputs
In real-world usage, this manifests as:
The AI forgetting constraints mentioned earlier in the conversation
Mixing up details from different versions of a document we're working on
Getting stuck in repetitive patterns that require a fresh start to break
For simple factual queries, this might not matter. But for creative writing, complex problem-solving, or nuanced analysis, it can dramatically impact quality.
How Different Platforms Handle Your Conversation
Before diving into strategies, it's important to understand how different AI platforms manage context:
Claude (Anthropic) keeps your entire conversation history in view until you hit the context limit. Everything you've said remains available, which provides comprehensive understanding but consumes your usage limits faster.
ChatGPT (OpenAI) uses a "rolling window" approach. Once you exceed the limit, older messages silently fall out of context, even though you still see them in your chat history. This is an invisible process - you don't get notified when something drops out of context.
Gemini (Google) works similarly to ChatGPT, with Gemini Flash 2.0 offering that massive 1 million token window.
This distinction dramatically affects how you should approach these tools.
Your Context Management Toolbox
Rather than letting these limitations frustrate you, I've developed a set of practical techniques that transform how effectively you can work with AI. Here are the four most powerful tools in your arsenal:
Tool 1: The Strategic Fresh Start
Many users avoid starting new conversations, fearing they'll lose valuable context. But starting fresh is often the most effective approach, and easier than you might think.
In a long conversation, the AI must wade through everything to find what matters, with its performance degrading along the way. In a new conversation with just the relevant information, it can focus entirely on what you need.
Real-world example: When I'm drafting an article, I often start with a general outline in one conversation. Once I have that structure, I'll start a fresh conversation for each major section, copying in just the outline points relevant to that section. The focused context results in much higher quality writing than trying to draft the entire article in a single, lengthy chat.
Tool 2: The Scroll-and-Edit Technique
One of the most powerful but overlooked techniques is scrolling back and editing earlier messages instead of adding new ones.
This approach:
Keeps the context focused by modifying your original instructions
Breaks patterns when the AI gets stuck in repetitive responses
Saves resources, especially with Claude
Eliminates confusion about which version you're working on
I use this constantly when refining documents or debugging code. Rather than having multiple versions floating around in the context, I update my original request with new specifications.
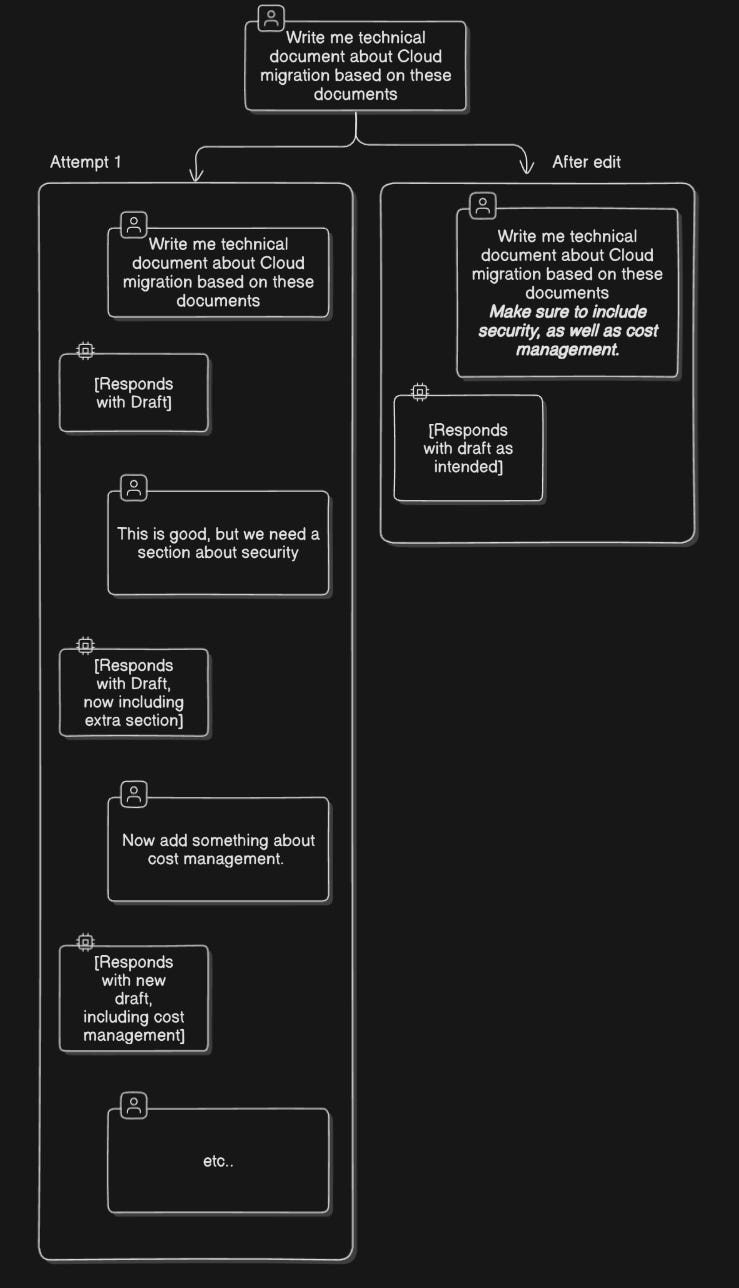
You're debugging Python code with ChatGPT. Initially, you say:
"Help me write Python code to analyze sales data."
The AI generates code, but it's missing visualization. Instead of adding new prompts repeatedly, you scroll up and edit the original request:
"Help me write Python code to analyze sales data and include visualizations using matplotlib."
The AI now generates comprehensive code without confusion.
Example transformation:
Tool 3: Strategic Formatting
When working with longer contexts, how you format your information dramatically impacts how well the AI can navigate it.
Effective formatting techniques include:
Using headings (
# Section Title) to divide your contentBold or italic text to emphasize key points
HTML-style tags (
<important>critical information</important>) for critical contentNumbered lists for sequential steps
These elements act like signposts for the model, making it much easier to reference specific parts of your conversation.
Tool 4: Platform-Specific Optimization
Different AI platforms respond best to different structures. Here's what works best:
For Claude:
<role>Define role</role>
<documents>Main content</documents>
<task>Specific instructions</task>
For ChatGPT/GPT-4:
[Examples/demonstrations]
[Context/constraints]
[Specific request]
For Mistral:
System role/context first
Background information
Specific question or request last
For all platforms: Context-first approaches generally outperform instruction-first approaches, as models pay more attention to what comes earlier in the context.
But what about RAG
For very long documents, many systems use RAG (Retrieval-Augmented Generation) to pull only relevant portions rather than processing everything. Simply put, instead of loading the full document into context, RAG could solve this problem by only fetching relevant sections. ChatGPT does this behind the scenes for long conversations.
When RAG works well:
Simple factual queries about specific points in a document
Situations where speed matters more than comprehensiveness
When working with very large corpora beyond context limits
But RAG isn’t perfect:
Suppose you upload an extensive product review document to ChatGPT. When asking a specific fact ("What's the product's weight?"), ChatGPT answers correctly via RAG.
But when you ask, "Does the reviewer generally recommend this product?" ChatGPT struggles, because the reviewer’s nuanced opinion spans multiple sections and subtle narrative cues, which RAG struggles to capture fully.
In short:
You don't know what's being used: Unlike full document ingestion (as with Claude), you can't be certain which parts of your document the system has retrieved and considered.
Missing the bigger picture: RAG often misses broader themes, narrative arcs, and connections that span across multiple sections of text. It's like trying to understand a story by reading random paragraphs—you might miss crucial development and context.
Generalized RAG is hard to perfect: Building a retrieval system that works well across all types of content is extremely challenging, which is why custom-built RAG systems often outperform general ones.
Your Action Plan
Based on everything we've covered, here's your practical action plan for more effective context management:
Don't fear the fresh start - Beginning a new conversation with just the relevant context often produces better results than continuing a bloated one.
Master the scroll-and-edit technique - When refining work, modify your initial prompt rather than adding new messages.
Structure strategically - Use headings, lists, and other formatting to help the AI quickly locate important information.
Place context before instructions - Models pay more attention to earlier content, so put your background information first.
Be concise - Include only what's necessary. More context isn't always better, and can actively hurt performance.
Quality over quantity - A few minutes spent extra on curation of what you’re passing on to the model can save much more down the line as the model will respond with more high-quality answers.
Use summaries as bridges - If you do start fresh, ask the AI to summarize key points from your previous conversation to include in the new one.
Label versions clearly - When working through iterations, use explicit labels like "V2" or "latest draft" to avoid confusion.
I've found these techniques transform not just the quality of AI outputs, but also how efficiently I can work with these tools. What started as frustrating limitations became opportunities to develop more effective workflows.
What are your experiences with managing AI conversations? Have you found other techniques that work well? I'd love to hear your thoughts!